Resource retrieval
Get the pre-trained net:
Basic usage
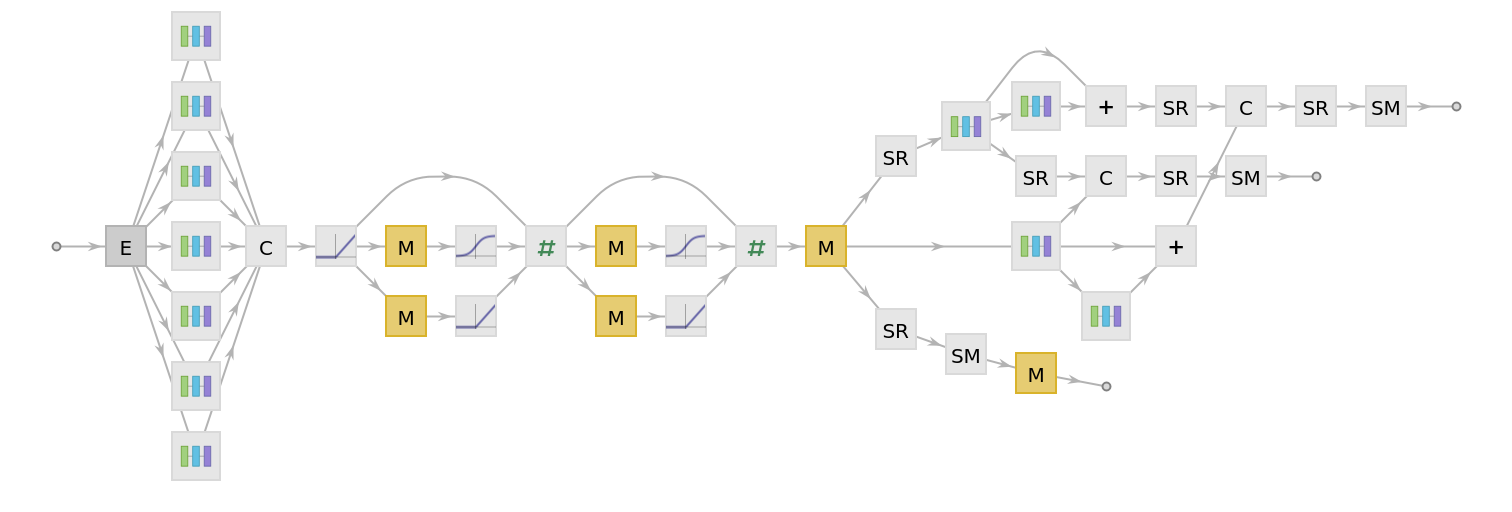
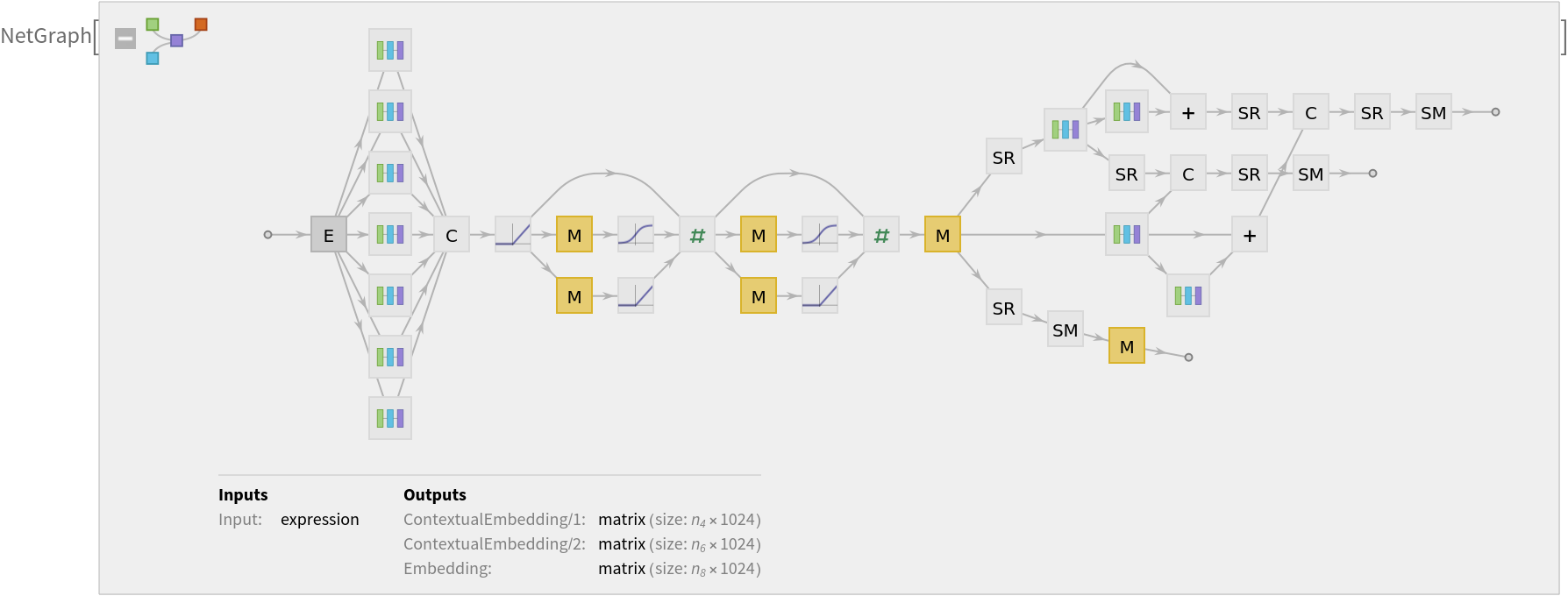
For each token, the net produces three length-1024 feature vectors: one that is context-independent (port "Embedding") and two that are contextual (ports "ContextualEmbedding/1" and "ContextualEmbedding/2").
Input strings are tokenized, meaning they are split into tokens that are words and punctuation marks:
Pre-tokenized inputs can be given using TextElement:
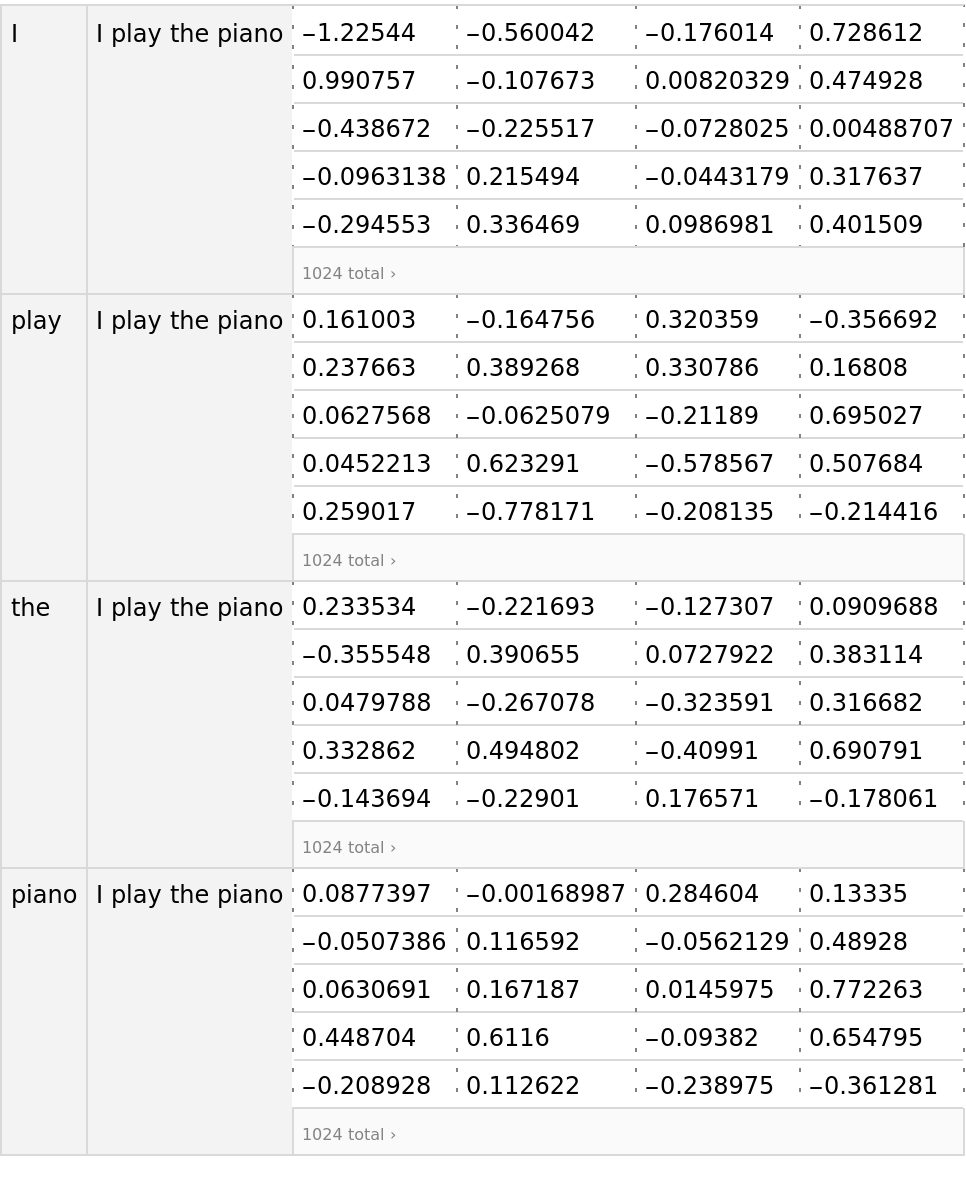
The representation of the same word in two different sentences is different. Extract the embeddings for a different sentence:
The context-independent embedding for the same word is the same, whatever the surrounding text is. For instance, for the word "Hello":
The context-dependent embeddings are different for the same word in two different sentences:
The recommended usage is to take a (possibly weighted) average of the embeddings:
Word analogies without context
Extract the non-contextual part of the net:
Precompute the context-independent embeddings for a list of common words (if available, set TargetDevice -> "GPU" for faster evaluation time):
Find the five nearest words to "king":
Man is to king as woman is to:
Visualize the similarity between the words using the net as a feature extractor:
Word analogies in context
Define a function that shows the word in context along with the average of its embeddings:
Check the result on a sentence:
Define a function to find the nearest word in context in a set of sentences, for a given word in context:
Find the semantically nearest word to the word "play" in "I play the piano":
Find the semantically nearest word to the word "set" in "The set of values higher than a threshold":
Train a model with the word embeddings
Take text-processing dataset:
Pre-compute the ELMo vectors on the training and the validation dataset (if available, GPU is recommended):
Define a network that takes word vectors instead of strings for the text-processing task:
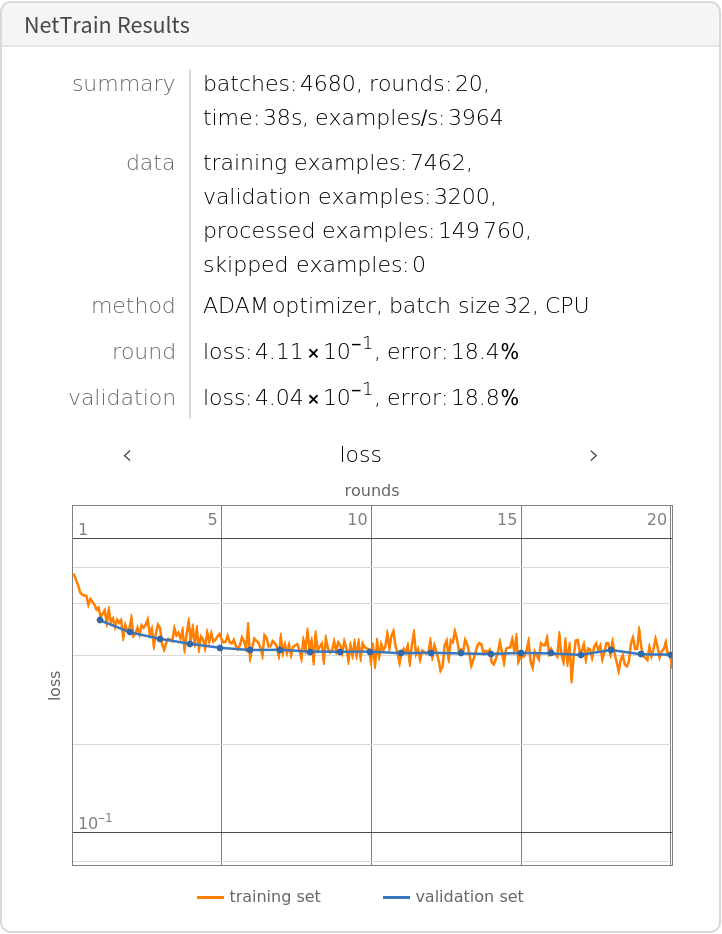
Train the network on the pre-computed ELMo vectors:
Check the classification error rate on the validation data:
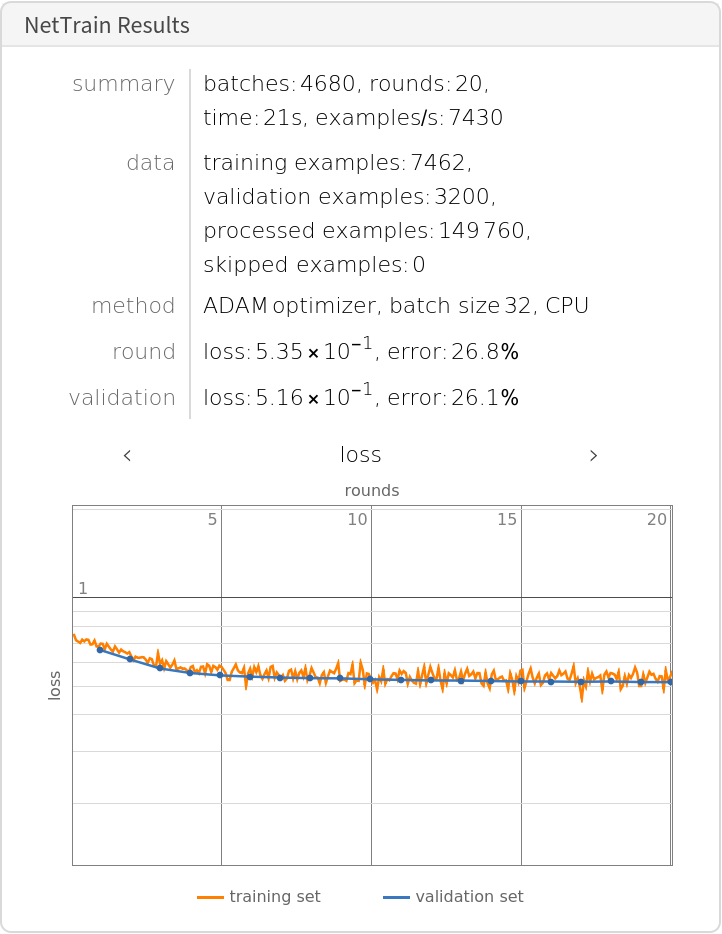
Compare the results with the performance of the same model trained on context-independent embeddings:
Net information
Inspect the number of parameters of all arrays in the net:
Obtain the total number of parameters:
Obtain the layer type counts:
Display the summary graphic:
Export to MXNet
Export the net into a format that can be opened in MXNet:
Export also creates a net.params file containing parameters:
Get the size of the parameter file:
The size is similar to the byte count of the resource object:


![embeddings2 = NetModel["ELMo Contextual Word Representations Trained on 1B Word \
Benchmark"][TextElement[{"Hello", "neighbor"}]]](https://www.wolframcloud.com/obj/resourcesystem/images/082/0829ac5c-f1aa-4dbc-88b1-9340a5eb88d0/0b556fb60e136f16.png)


![netNonContextual = NetTake[NetModel[
"ELMo Contextual Word Representations Trained on 1B Word \
Benchmark"], {NetPort["Input"], "embedding"}]](https://www.wolframcloud.com/obj/resourcesystem/images/082/0829ac5c-f1aa-4dbc-88b1-9340a5eb88d0/004f639a0ac8b9b7.png)

![animals = {"alligator", "bear", Sequence[
"bird", "bee", "camel", "zebra", "crocodile", "rhinoceros", "giraffe", "dolphin", "duck", "eagle", "elephant", "fish", "fly"]};](https://www.wolframcloud.com/obj/resourcesystem/images/082/0829ac5c-f1aa-4dbc-88b1-9340a5eb88d0/4ed13bb878b1fddf.png)
![fruits = {"apple", "apricot", Sequence[
"avocado", "banana", "blackberry", "cherry", "coconut", "cranberry", "grape", "mango", "melon", "papaya", "peach", "pineapple", "raspberry", "strawberry", "fig"]};](https://www.wolframcloud.com/obj/resourcesystem/images/082/0829ac5c-f1aa-4dbc-88b1-9340a5eb88d0/0eeac5311b452145.png)

![netevaluateWithContext[sentence_String] := With[{tokenizedSentence = TextElement[StringSplit[sentence]]},
AssociationThread[
Thread[{First[tokenizedSentence], sentence}],
Mean@Values@(NetModel[
"ELMo Contextual Word Representations Trained on 1B Word \
Benchmark"][tokenizedSentence])
]
]](https://www.wolframcloud.com/obj/resourcesystem/images/082/0829ac5c-f1aa-4dbc-88b1-9340a5eb88d0/0d4729566e3d4fba.png)
![findSemanticNearestWord[{word_, context_}, otherSentences_] := First@Nearest[
Association[Join @@ Map[netevaluateWithContext, otherSentences]],
netevaluateWithContext[context][{word, context}]
]](https://www.wolframcloud.com/obj/resourcesystem/images/082/0829ac5c-f1aa-4dbc-88b1-9340a5eb88d0/6d521c8964899785.png)
![findSemanticNearestWord[{"play", "I play the piano"},
{"This was a nice play", "Guitar can be played with a pick"}
]](https://www.wolframcloud.com/obj/resourcesystem/images/082/0829ac5c-f1aa-4dbc-88b1-9340a5eb88d0/422387addb76b060.png)
![findSemanticNearestWord[{"set", "The set of values higher than a threshold"},
{"They set the clock", "This ensemble of items belongs to her"}
]](https://www.wolframcloud.com/obj/resourcesystem/images/082/0829ac5c-f1aa-4dbc-88b1-9340a5eb88d0/6163f265fe77a844.png)
![trainingDataELMo = Total[Values[
NetModel[
"ELMo Contextual Word Representations Trained on 1B Word \
Benchmark"][Keys[trainingData], TargetDevice -> "CPU"]]/3.] -> Values[trainingData];](https://www.wolframcloud.com/obj/resourcesystem/images/082/0829ac5c-f1aa-4dbc-88b1-9340a5eb88d0/4d4b8929b2f4d72f.png)
![validationDataELMo = Total[Values[
NetModel[
"ELMo Contextual Word Representations Trained on 1B Word \
Benchmark"][Keys[validationData], TargetDevice -> "CPU"]]/3.] -> Values[validationData];](https://www.wolframcloud.com/obj/resourcesystem/images/082/0829ac5c-f1aa-4dbc-88b1-9340a5eb88d0/2f7d14210dbb4608.png)
![netArchitecture = NetChain[{DropoutLayer[], NetMapOperator[2], AggregationLayer[Max, 1], SoftmaxLayer[]}, "Output" -> NetDecoder[{"Class", {"negative", "positive"}}]]](https://www.wolframcloud.com/obj/resourcesystem/images/082/0829ac5c-f1aa-4dbc-88b1-9340a5eb88d0/4c70df08cabae6dc.png)
![trainingDataGlove = Thread@Rule[
NetModel[
"GloVe 300-Dimensional Word Vectors Trained on Wikipedia and \
Gigaword 5 Data"][Keys[trainingData]],
Values[trainingData]
];](https://www.wolframcloud.com/obj/resourcesystem/images/082/0829ac5c-f1aa-4dbc-88b1-9340a5eb88d0/573aacf6c0f24639.png)
![validationDataGlove = Thread@Rule[
NetModel[
"GloVe 300-Dimensional Word Vectors Trained on Wikipedia and \
Gigaword 5 Data"][Keys[validationData]],
Values[validationData]
];](https://www.wolframcloud.com/obj/resourcesystem/images/082/0829ac5c-f1aa-4dbc-88b1-9340a5eb88d0/3045594f8bdaf25f.png)
![NetInformation[
NetModel["ELMo Contextual Word Representations Trained on 1B Word \
Benchmark"], "ArraysElementCounts"]](https://www.wolframcloud.com/obj/resourcesystem/images/082/0829ac5c-f1aa-4dbc-88b1-9340a5eb88d0/22f560cf7cd41729.png)

![NetInformation[
NetModel["ELMo Contextual Word Representations Trained on 1B Word \
Benchmark"], "ArraysTotalElementCount"]](https://www.wolframcloud.com/obj/resourcesystem/images/082/0829ac5c-f1aa-4dbc-88b1-9340a5eb88d0/0b0324b020658a86.png)
![NetInformation[
NetModel["ELMo Contextual Word Representations Trained on 1B Word \
Benchmark"], "LayerTypeCounts"]](https://www.wolframcloud.com/obj/resourcesystem/images/082/0829ac5c-f1aa-4dbc-88b1-9340a5eb88d0/00071a5acd317fd7.png)

![NetInformation[
NetModel["ELMo Contextual Word Representations Trained on 1B Word \
Benchmark"], "SummaryGraphic"]](https://www.wolframcloud.com/obj/resourcesystem/images/082/0829ac5c-f1aa-4dbc-88b1-9340a5eb88d0/1a492991c6fd2705.png)