Wolfram Neural Net Repository
Immediate Computable Access to Neural Net Models
Identify the main object in an image
Released in 2018 by researchers at Google, these models improve upon the performance of previous MobileNet models. The models introduce new inverted residual structures featuring shortcut connections between the thin bottleneck layers. Like their predecessors, the expansion layers use lightweight depthwise convolutions.
Number of models: 22
All measures are relative to the ImageNet Large Scale Visual Recognition Challenge 2012 dataset.
Model "mobileNetV2_1.4_224" achieves 75.0% top-1 and 92.5% top-5 accuracy.
Model "mobileNetV2_1.3_224" achieves 74.4% top-1 and 92.1% top-5 accuracy.
Model "mobileNetV2_1.0_224" achieves 71.8% top-1 and 91.0% top-5 accuracy.
Model "mobileNetV2_1.0_192" achieves 70.7% top-1 and 90.1% top-5 accuracy.
Model "mobileNetV2_1.0_160" achieves 68.8% top-1 and 89.0% top-5 accuracy.
Model "mobileNetV2_1.0_128" achieves 65.3% top-1 and 86.9% top-5 accuracy.
Model "mobileNetV2_1.0_96" achieves 60.3% top-1 and 83.2% top-5 accuracy.
Model "mobileNetV2_0.75_224" achieves 69.8% top-1 and 89.6% top-5 accuracy.
Model "mobileNetV2_0.75_192" achieves 68.7% top-1 and 88.9% top-5 accuracy.
Model "mobileNetV2_0.75_160" achieves 66.4% top-1 and 87.3% top-5 accuracy.
Model "mobileNetV2_0.75_128" achieves 63.2% top-1 and 85.3% top-5 accuracy.
Model "mobileNetV2_0.75_96" achieves 58.8% top-1 and 81.6% top-5 accuracy.
Model "mobileNetV2_0.5_224" achieves 65.4% top-1 and 86.4% top-5 accuracy.
Model "mobileNetV2_0.5_192" achieves 63.9% top-1 and 85.4% top-5 accuracy.
Model "mobileNetV2_0.5_160" achieves 61.0% top-1 and 83.2% top-5 accuracy.
Model "mobileNetV2_0.5_128" achieves 57.7% top-1 and 80.8% top-5 accuracy.
Model "mobileNetV2_0.5_96" achieves 51.2% top-1 and 75.8% top-5 accuracy.
Model "mobileNetV2_0.35_224" achieves 60.3% top-1 and 82.9% top-5 accuracy.
Model "mobileNetV2_0.35_192" achieves 58.2% top-1 and 81.2% top-5 accuracy.
Model "mobileNetV2_0.35_160" achieves 55.7% top-1 and 79.1% top-5 accuracy.
Model "mobileNetV2_0.35_128" achieves 50.8% top-1 and 75.0% top-5 accuracy.
Model "mobileNetV2_0.35_96" achieves 45.5% top-1 and 70.4% top-5 accuracy.
Get the pre-trained net:
| In[1]:= |
| Out[1]= |  |
This model consists of a family of individual nets, each identified by a specific parameter combination. Inspect the available parameters:
| In[2]:= |
| Out[2]= |  |
Pick a non-default net by specifying the parameters:
| In[3]:= |
| Out[3]= |  |
Pick a non-default uninitialized net:
| In[4]:= |
| Out[4]= |  |
Classify an image:
| In[5]:= | ![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/9ad83e1a-fb2f-4e86-9941-87f3da1fb5c7"]](https://www.wolframcloud.com/obj/resourcesystem/images/036/0361f9ea-8a2a-4a86-b270-733c1f95d38e/037b99648d512a55.png) |
| Out[5]= |
The prediction is an Entity object, which can be queried:
| In[6]:= |
| Out[6]= |
Get a list of available properties of the predicted Entity:
| In[7]:= |
| Out[7]= |  |
Obtain the probabilities of the ten most likely entities predicted by the net:
| In[8]:= | ![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/da5b5dba-4895-4e4b-8a25-527b554e1c5d"]](https://www.wolframcloud.com/obj/resourcesystem/images/036/0361f9ea-8a2a-4a86-b270-733c1f95d38e/755705c1ea19d3ab.png) |
| Out[8]= | 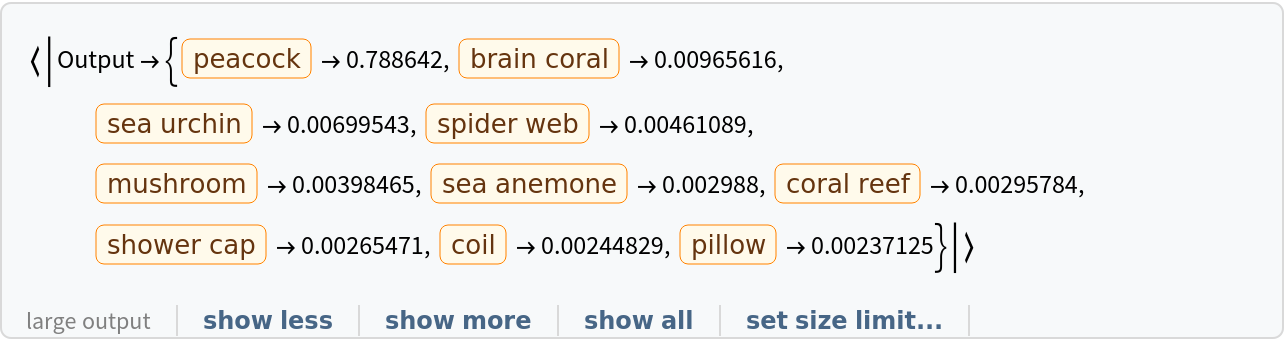 |
An object outside the list of the ImageNet classes will be misidentified:
| In[9]:= | ![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/e2c7d20d-b2cd-411d-b12b-f11eebe710b3"]](https://www.wolframcloud.com/obj/resourcesystem/images/036/0361f9ea-8a2a-4a86-b270-733c1f95d38e/146e761ab4c38c48.png) |
| Out[9]= |
Obtain the list of names of all available classes:
| In[10]:= | ![EntityValue[
NetExtract[
NetModel["MobileNet V2 Trained on ImageNet Competition Data"], "Output"][["Labels"]], "Name"]](https://www.wolframcloud.com/obj/resourcesystem/images/036/0361f9ea-8a2a-4a86-b270-733c1f95d38e/0c8c2e847a9d8914.png) |
| Out[10]= |  |
Remove the last three layers of the trained net so that the net produces a vector representation of an image:
| In[11]:= |
| Out[11]= |  |
Get a set of images:
| In[12]:= | ![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/50baa58c-0677-4b08-ba99-5506105e21a9"]](https://www.wolframcloud.com/obj/resourcesystem/images/036/0361f9ea-8a2a-4a86-b270-733c1f95d38e/537bebdb35a73750.png) |
Visualize the features of a set of images:
| In[13]:= |
| Out[13]= |  |
Extract the weights of the first convolutional layer in the trained net:
| In[14]:= |
| Out[14]= |
Visualize the weights as a list of 48 images of size 3x3:
| In[15]:= |
| Out[15]= | 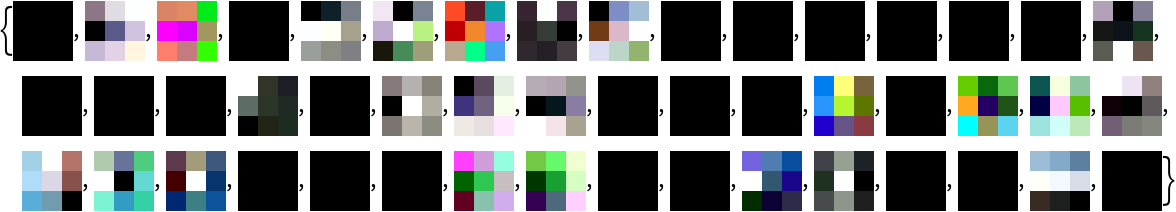 |
Use the pre-trained model to build a classifier for telling apart images of dogs and cats. Create a test set and a training set:
| In[16]:= | ![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/01ec674d-be15-4b55-94d1-897cbe0ea5f0"]](https://www.wolframcloud.com/obj/resourcesystem/images/036/0361f9ea-8a2a-4a86-b270-733c1f95d38e/2a2cbd2549a918bd.png) |
| In[17]:= | ![(* Evaluate this cell to get the example input *) CloudGet["https://www.wolframcloud.com/obj/a0bfae48-7d1a-4955-87c2-f77253642017"]](https://www.wolframcloud.com/obj/resourcesystem/images/036/0361f9ea-8a2a-4a86-b270-733c1f95d38e/13f6f01a7175a589.png) |
Remove the linear layer from the pre-trained net:
| In[18]:= |
| Out[18]= |  |
Create a new net composed of the pre-trained net followed by a linear layer and a softmax layer:
| In[19]:= | ![newNet = NetChain[<|"pretrainedNet" -> tempNet, "linearNew" -> LinearLayer[], "softmax" -> SoftmaxLayer[]|>, "Output" -> NetDecoder[{"Class", {"cat", "dog"}}]]](https://www.wolframcloud.com/obj/resourcesystem/images/036/0361f9ea-8a2a-4a86-b270-733c1f95d38e/1a3bfaefa43fa95e.png) |
| Out[19]= |  |
Train on the dataset, freezing all the weights except for those in the "linearNew" layer (use TargetDevice -> "GPU" for training on a GPU):
| In[20]:= |
| Out[20]= |  |
Perfect accuracy is obtained on the test set:
| In[21]:= |
| Out[21]= |
Inspect the number of parameters of all arrays in the net:
| In[22]:= |
| Out[22]= |  |
Obtain the total number of parameters:
| In[23]:= |
| Out[23]= |
Obtain the layer type counts:
| In[24]:= |
| Out[24]= |
Display the summary graphic:
| In[25]:= |
| Out[25]= |
Wolfram Language 12.0 (April 2019) or above